Hill Climbing termasuk dalam metode Uninformed Search, ia menggunakan metode mencari nilai yang lebih baik dari sebelumnya, cara ini biasanya diterapkan pada tree.
Silahkan di lihat gambarnya.
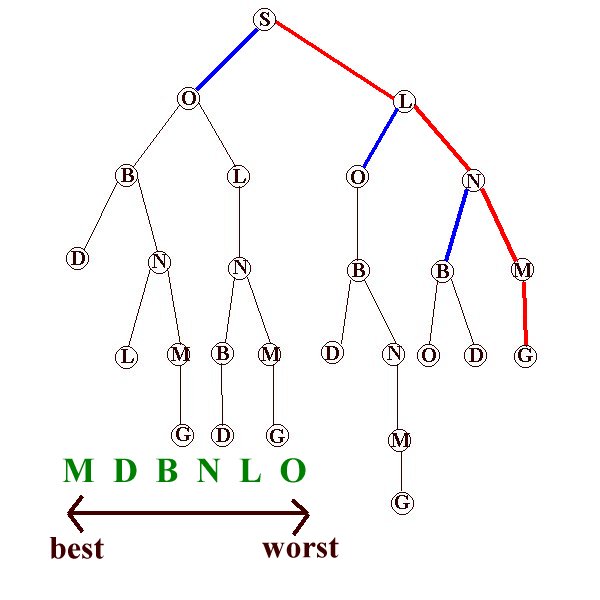
Dari gambar di atas dapat kita simpulkan cara kerjanya, pertama kita tentukan dulu aturan(list) mana yang terbaik dan terburuknya. Gambar ini menentukan M-D-B-N-L-O sebagai prioritasnya.
Selanjutnya ketika kita memulai pencarian(dari root = S(start)), kita akan menentukan langkah selanjutnya dengan patokan aturan tersebut, hingga kita menemukan G(goal)nya.
Solusi ini jelas tidak akan optimal untuk mencari suatu solusi, tapi kita dapat "mengakali" nya dengan cara memperbanyak climbernya(startnya dari beberapa tempat), dengan memperbanyak climber kita dapat meningkatkan kemungkinan mendapatkan solusi terbaik.
Read More...
Jumat, 26 November 2010
Hill Climbing Search
Kamis, 25 November 2010
Depth First Search
Termasuk dalam metode Uninformed Search, berlawanan cara dengan metode Breadth First Search yang saya bahas sebelumnya.
Ini gambar animasinya.
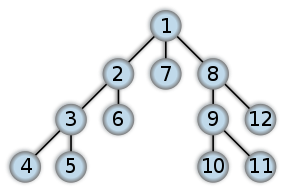
Metode ini akan mencari dulu di satu sisi, hingga kedalaman yang paling jauh, lalu akan melakukan backtrack.
Keuntungan :
Kerugian :
Read More...
Breadth First Search
Metode pencarian ini merpakan metode Uninformed Search, metode ini mencari nilai terbaik dengan cara melihat per baris.
Silahkan melihat gambar berikut agar lebih jelas.

Dapat di lihat bahwa setiap akan turun, akan memeriksa anaknya, lalu di simpan.
Cara penyimpanan :
a
bc (node anak dari root)
cde (node c + node anak dari b)
defg (node anak dari b + node anak dari c)
dfgh (dst....*hingga ketemu goalnya.)
Keuntungan :
Kerugian :
Read More...
Rabu, 24 November 2010
Segmented Sieve of Eratosthenes
Segmented Sieve of Eratosthenes adalah pengembangan dari Sieve of Eratosthenes, bila bilangan prima yang di cari tidak di mulai dari angka 0.
Contohnya "Tuliskan bilangan Prima dari 999900000 sampai 1000000000" coba bayangkan kompleksitas nya kalau harus mulai dari 0. XD.
Ini source code upgrade an Sieve of Eratosthenes" saya :D
#include <iostream>
#include <math.h>
typedef long long LL;
using namespace std;
LL N,M;
bool Prima[1000000000];
int main()
{
cout<<"Masukan angka minimal bilangan prima = ";cin>>N;
cout<<"Masukan angka maximal bilangan prima = ";cin>>M;
for(LL i=N;i<M;i++)
Prima[i] = true;
cout<<"Bilangan Prima dari "<<N<<" - "<<M<<" adalah : ";
Prima[0] = false;
Prima[1] = false;
for(LL i=2;i<sqrt(M);i++)
for(LL j=N;j<M;j++)
if(Prima[j] && ((j/i)*i == j))
{
j += i;
while(j < M)
{
if(Prima[j])
Prima[j] = false;
j += i;
}
}
for(int i=N;i<M;i++)
if(Prima[i])
cout<<i<<endl;
return 0;
}
Read More...
Buble Sort
Buble adalah metode pengurutan paling simpel (menurut saya), mengecek apakah ada yang lebih besar atau tidak, lalu di tukar, tapi dengan kasus terburuk kompleksitasnya mencapai O(N2).
Ini ada contoh source code C++ saya
#include <iostream>
using namespace std;
int main()
{
int data[100],n;
cout<<"Berapa banyak data = ";cin>>n;
cout<<"Masukan data yang akan di sorting = ";
for(int i=0;i<n;i++)
cin>>data[i];
for(int i=0;i<n;i++)
for(int j=i;j<n;j++)
if(data[i] > data[j])
swap(data[i],data[j]);
for(int i=0;i<n;i++)
cout<<data[i]<<' ';
return 0;
}
Read More...
Html Code Converter
Ketika pertama kali "mempaste" kan source code ke blog, ada sesuatu yang aneh, apa yah ??? pas saya lihat - lihat dengan jelas, ternyata semua html code nya di convert otomatis...XD
Setelah cari - cari referensi untuk memasang code converter sendiri di blog, akhirnya ketemu juga :D, jadi ga perlu cari - cari web buat convert.
Ini dia....
Read More...
Merge Sort
Merge sort merupakan salah satu metode sorting yang paling stabil, kompleksitas nya juga O(n log n) untuk kasus terburuk dan terbaik sekalipun.
Merge sort menggunakan metode Divide and Conquer untuk menyelesaikan penyusunannya, jadi data akan di pecah - pecah menjadi sangat kecil dan di selesaikan satu per satu.
Ini ada suatu gambar yang saya dapatkan dari wikipedia, cukup untuk membuat kita mudah mengerti maksud dari sorting ini.

Sudah bisa mengerti gambar ini ??
Lalu bagaimana mengimplementasikan dalam sebuah program ?
Silahkan cek source code yang saya buat dengan C++
#include <iostream>
using namespace std;
int data[100];
void mergeSort(int awal, int mid, int akhir)
{
cout<<endl;
int temp[100], tempAwal = awal, tempMid = mid, i = 0;
while(tempAwal < mid && tempMid < akhir)
{
if(data[tempAwal] < data[tempMid])
temp[i] = data[tempAwal],tempAwal++;
else
temp[i] = data[tempMid],tempMid++;
i++;
}
while(tempAwal < mid) //kalau masih ada yang sisa
temp[i] = data[tempAwal],tempAwal++,i++;
while(tempMid < akhir)
temp[i] = data[tempMid],tempMid++,i++;
for(int j=0,k=awal;j<i,k<akhir;j++,k++) //mengembalikan ke array semula, tapi
cout<<data[k]<<' '<<temp[j]<<endl, data[k] = temp[j]; //sudah urut
}
void merge(int awal, int akhir) //membagi data secara rekursif
{
if(akhir-awal != 1)
{
int mid = (awal+akhir)/2;
merge(awal, mid);
merge(mid, akhir);
mergeSort(awal, mid, akhir);
}
}
int main()
{
int n;
cout<<"Masukan banya data = ";cin>>n;
cout<<"Masukan data yang akan di susun = ";
for(int i=0;i<n;i++)
cin>>data[i];
merge(0,n);
for(int i=0;i<n;i++)
cout<<data[i]<<' ';
return 0;
}
Read More...
Selasa, 23 November 2010
Daftar Algoritma
Algoritma adalah dasar dari pemrograman, jika anda sudah cukup mahir di algoritma, untuk "berekspresi" di berbagai bahasa pemrograman sangatlah mudah...
Ini ada daftar algoritma yang saya dapatkan dari wikipedia.
Sebisa mungkin saya akan men-translate-kan dan menringkasnya menjadi mudah di mengerti, karena saya lihat tutorial tentang algoritma berbahasa indonesia masih sangat sedikit sekali. :D
Read More...
Senin, 22 November 2010
Sieve Of Eratosthenes
Sieve of Erastosthenes adalah suatu Number Theoritic Algorithm khusus untuk mencari bilangan prima.
Algoritma ini merupakan yang tercepat di bidangnya, karena menggunakan list data untuk menyimpan bilangan prima yang sudah di temukan dan menghapus bilangan kelipatan prima tersebut.
Contoh : 3 adalah bilangan prima, kelipatan 3 pasti bukan bilangan prima, jangan tanya kenapa !! :D
dah ngerti kan ???
ini ada contoh source code yang saya buat :D
#include <iostream>
#include <math.h>
typedef long long LL;
using namespace std;
LL N;
bool Prima[1000000000];
int main()
{
cout<<"Masukan angka maximal bilangan prima yang anda inginkan = ";cin>>N;
for(LL i=0;i<N;i++) // semua di set true dulu.
Prima[i] = true;
Prima[0] = false;
Prima[1] = false;
cout<<"Bilangan Prima dari 1 - "<<N<<" adalah : "<<endl;
for(LL i=2*2;i<N;i+=2) //bilangan prima pasti bukan bilangan genap,
Prima[i] = false; //kecuali 2. Jadi kelpatan 2 di buang dulu.
for(LL i=3;i<sqrt(N);i+=2) //disini langsung mencari bilangan ganjil saja.
if(Prima[i])
for(LL j=i*i;j<N;j+=i)
Prima[j] = false;
for(LL i=2;i<N;i++)
if(Prima[i])
cout<<i<<endl;
return 0;
}
Read More...